 2006, Vol. 32
2006, Vol. 32 近20年来,大气污染预报模式的研究得到了很大的发展,从过去的统计预报模式,已发展到今天的中尺度气象预报模式、大气污染扩散模式和光化学模式相结合的空气污染预报模式和非静稳多箱格大气污染浓度预报和潜势预报系统CAPPS模式。大气预报模式主要可以归为潜势预报、统计预报及数值模式预报三类。统计预测方法多是线形模型,难以模拟复杂多变的大气污染变化。神经网络较统计方法能更好地模拟大气污染因素的非线形关系,在大气污染预报应用中取得较好结果[1]。然而,神经网络具有推广能力差、过拟合、易于陷人局部最优、寻找结构参数复杂等缺点。支持向量机(SVM),是Vapnik开发的基于统计学习理论的新一代机器学习技术[2],在解决小样本、非线性问题中表现出独特优势。其遵循结构风险最小化原则,预测性能和推广能力优于神经网络,因而成为应用领域研究的热点。陈永义和冯汉中[3]率先将SVM引入了气象领域。目前,SVM在气象上的应用主要是短期预报、实时短期预报业务[4-6]等方面。本文通过实例论证,探讨支持向量回归方法应用于环境空气质量预报的可行性,并利用交叉验证和网格搜索的方法确定支持向量机的超参数,从而确保模型的预测精度。
1 支持向量机回归方法的基本原理给定s组样本数据{xk,yk},k=1,2,…,s,其中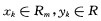
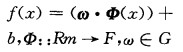
|
(1) |
式中:(•)为内积运算;b:偏置项。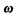
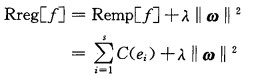
|
(2) |
式中:ei=f(xi)-yi,s:样本容量,C(ei):损失函数,λ:规则化常数。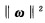
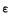
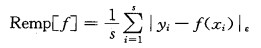
|
(3) |
式(2)等价于求解如下的优化问题。
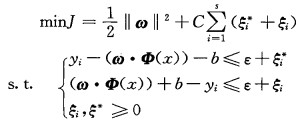
|
(4) |
式中: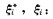
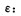
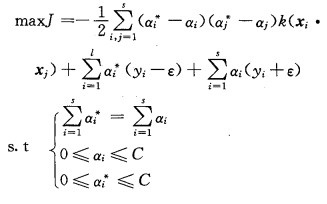
|
(5) |
αi*和αi为两组Lagrange乘子,即最小化Rreg的解。求解上述凸二次规划得到的非线性映射可表示为:
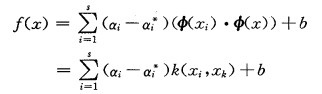
|
(6) |
其中: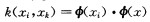
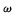
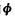
建立基于支持向量机的大气污染物浓度变化的预报模型,关键问题是输入模式的确定、训练样本的选取以及模型结构参数的选取。本文拟建立PM10,NO2, SO2日均浓度值的预报模型。
2.1 输入因子的选取大气污染物浓度变化主要影响因素是污染源和污染源排放的污染气象条件等。根据资料及历史经验[7, 8],确定当日污染物浓度(PM10,NO2, SO2)预报模型的输入向量为前一天该污染物的日均浓度、前一天地面平均风速、前一天最低温度梯度、前一天平均温度梯度、前一天平均湿度、前一天平均总云量、前一天污染源的源强7个因子。
2.2 基于SVM回归的大气污染预报模型(1) 确定支持向量机的核函数类型
选择合适的核函数,可提高预测精度,降低噪声的影响。通常认为RBF核函数优于其他核函数,具有性能好且稳定和调节参数较少等优点[9]。因此,本文使用RBF核函数的支持向量回归模型。σ对回归超平面的形成有直接影响,目前没有统一方法来确定σ大小。
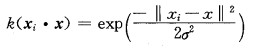
|
(7) |
(2) 支持向量机预测模型的参数寻优
模型中C、σ、ε参数的选取,直接影响模型的预测性能和推广能力。目前尚没有通用的支持向量机参数选择模式,只能凭借经验和试验对比。多数文献随机选取,影响了模型的精度。本文利用多重交叉验证(k-fold cross validation)的方法和网格法(grid-search)[9]寻找C和σ。其原理是:将训练集分成k个子集(样本数量大致均匀),每个子集分别作为测试集,其余子集样本作为训练集,即建模k次,用k次的平均绝对误差评估模型性能,进而确定模型的最优参数对(C,σ)。网格法是对网格上的(C,σ)点穷举搜索,C和σ的步长呈指数级增长(例:C=2-10,2-9,…,210;σ=2-10,2-9, …,210)。不像其他启发式方法,网格搜索计算可并行进行,因而是一种较为实用有效的方法。
(3) 用训练样本训练具有优化参数的支持向量机预测器,获得支持向量,确定支持向量机的结构。
(4) 用训练过的支持向量预测器对测试样本预测。
3 预报试验分析 3.1 试验软件LIBSVM是台湾大学林智仁教授编写的软件,功能较全,提供源码,方便改进,提供SVM默认参数,国内外应用效果较好[9]。
3.2 预报实验用乌鲁木齐气象资料和同期大气环境检测资料实验。以PM10预测为例:把2003年的4、5、6月每日共91组数据作为训练样本,每组数据包含7个输入因子和1个PM10实际值。把2004年的4月每日共30组数据作为测试样本,每组数据包含7个输入因子,对每日的PM10进行预测。另两项污染物NO2, SO2的预测方法相同。
采用10重交叉验证和粗细网格法寻参。先在(C=2-10,2-9,…,210;σ=2-10,2-9, …,210)网格内大步长寻找较优参数,得性能较优点(C=21,σ=2-1),然后在此点附近网格内(C=2-1,2-0.75,…,23; σ=2-3,2-2.75,…,21)小步长搜索,得到最优点(C=21.75,σ=2-0.75)。依据经验确定训练误差e=0.001,并使用最优的C,σ值和训练样本建立预报模型,对测试样本的污染物浓度预测。最后即得到日污染物平均浓度的时间序列数据,如图 1~3所示。

|
图 1 2004年4月逐日PM10实测值与预测值浓度对比 |

|
图 2 2004年4月逐日NO2实测值与预测值浓度对比 |

|
图 3 2004年4月逐日SO2实测值与预测值浓度对比 |
(1) 图 1~3分别是PM10、NO2、SO2的实测值和预测值的对比。由图可以看出,各污染物的实测值和预测值符合得较好,各污染物绝对预报误差较小。模型对各污染物的浓度总体变化趋势反映较敏感。
分析数据后可知,PM10误差的来源主要受特殊天气的影响,例如沙尘暴及扬尘天气,气象预报的偏差也在不同程度上造成误差。图 1看出4月19-20日的扬尘天气对PMla浓度预测造成较大影响。4月中旬以来新疆北部地区气温持续上升,近半个月没有降水,地表疏松干燥,这也是扬尘、扬沙及沙尘暴天气产生的主要原因。
SO2的误差较突出。乌鲁木齐市的SO2污染主要为燃煤型,随着冬季采暖期的结束和污染排放源的减少而有很大程度削减。又源于其自身水溶性较NO2强的特点,因此受环境空气状况影响较大,一旦有风雨天气,其衰减辐度很大,引起相应的误差。
乌鲁木齐市的NO2污染水准较之SO2并不低,但是由于冬季被SO2的污染所掩盖。夏季来临,SO2的污染水平有所降低,加之气温和日照等气象条件较冬季大为改善,对于二次污染物NO2的生成有利,因此其污染程度也就体现无遗。从NO2浓度误差统计中得知:NO2的误差主要受特殊天气(风、雨等)的影响。
(2)PM10、NO2、SO2的实测值和预测值的线性相关系数为0.795、0.778、0.702(图略)。这表明SVMR模型处理大气污染物的非线性问题具有优势。由于本文对不同污染物均选取相同的气象因子作为训练样本,因此在对不同污染物的预测中,预测值与实测值间的相关性存在一定差异。
4 结论(1) RBF核函数的支持向量回归模型能很好捕捉大气污染物浓度与其影响因子的非线性关系,具有预报精度较髙和训练速度快的优点。但是大气污染物浓度预报的准确率受到预报模式本身、气象预报和环境预报准确率的影响,对重大天气变化的预报尚存一定局限。
(2) 多重交叉验证法和网格搜索法是寻找支持向量机模型参数的有效方法,也是确保模型预测精度的关键。
(3) 由于资料所限,对不同污染物均选取相同的气象因子,具有一定的局限性。今后改进的方向是采取定性和定量的方法筛选大气污染物浓度的影响因子。
(4) 支持向量机运用于大气污染预报的研究尚处于试验探索阶段,本文仅作了粗浅探讨。模型的推广还必须考虑样本容量、气候环境诸多因素进一步改进。
| [1] |
金龙. 人工神经网络技术发展及在大气科学领域的应用[J]. 气象科技, 2004, 32(6): 12-13. |
| [2] |
Vapnik V. N., 张学工译. 统计学习理论的本质[M]. 北京; 清华大学出版社, 2000.
|
| [3] |
冯汉中, 陈永义. 处理非线性分类和回归问题的一种新方法)(2)--支持向量机方法在天气预报中的应用[J]. 应用气象学报, 2004, 15(3): 356-365. |
| [4] |
冯汉中, 陈永义. 支持向量机回归方法在实时业务预报中的应用[J]. 气象, 2005, 31(2): 41-44. |
| [5] |
车怀敏. 用支持向量机方法作德阳降水预报[J]. 四川气象, 2005(2): 13-15. |
| [6] |
冯汉中, 杨淑群, 刘波. 支持向量机(SVM)方法在气象预报中的个例试验[J]. 四川气象, 2005(2): 9-12. |
| [7] |
王俭, 胡筱敏, 郑龙熙. 基于模型的大气污染预报方法的研究[J]. 环境科学研究, 2002, 15(5): 62-65. |
| [8] |
熊忠华, 陈琦, 郑秀梅. 基于遗传算法的人工神经网络大气环境评价[J]. 环境科学与技术, 2005, 28(4): 82-84. |
| [9] |
LIBSVM: a Library for support Vector Machines[OL]. Chih_ Chung, http://www.csie.ntu.edu.tw.
|